OpenAI déjà célèbre pour ses progrès dans la génération d’images (DALL-E) et dans la reconnaissance textuelle (notamment GPT-3) présente Whisper, un système de traduction « temps réel » extrêmement performant et accessible à tous.
Basé sur L’ASR (Automatic Speech Recognition), ce système Open Source est un véritable « bon en avant » dans les technologies liées à la traduction automatique.
Construit en partie sur du Machine Learning, le système a traité, épuré (bruits de fond et parasites) et appris (même les accents les plus compliqués) différentes langues sur un panel d’écoute de plus de 680 000 heures récoltées sur le WEB. Il réalise la transcription dans plusieurs langues, ainsi que la traduction de ces langues vers l’anglais.
Les progrès de la reconnaissance vocale ont été dynamisés par la
développement de plusieurs techniques de pré-aprentissage en mode dit « non supervisé » illustrées notamment par la solution Wav2Vec 2.0.
Initiée il y a deux ans par Facebook, elle permet de s’affranchir du long et fastidieux travail de « labellisation » des morceaux qui nécessite des centaines de milliers d’heures d’apprentissage pour une seule langue. Grâce à l’utilisation du Machine Learning, Wav2Vec permet automatiquement de générer les autres langues liées au fragment de sons qui sont traités en « temps réel ».
A partir d’un Dataset de label assez réduit et après l’apprentissage d’environ 53 000 heures de sons, la solution génère et insère via des encodeurs spécialisés, le fragment de spectre audio correspondant à la langue directement dans le flux sonore. L’algorithme permet également de prédire quelles sont les séquences suivantes à « compléter » par les morceaux de sons correspondant à la langue choisie. Sur une période de 10 minutes le taux d’erreurs est d’environ 6% et il décroit lorsque le volume du Dataset augmente.
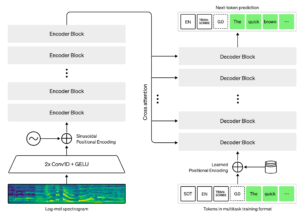
Decoupage des fragments de sons
Whisper améliore encore les performances de Wav2Vec avec un Dataset plus important et une possibilité d’intégrer également les accents des différentes langues (le patois par exemple).
Whisper autorise les développeurs à utiliser sa plateforme pour créer et enrichir encore cette capacité d’apprentissage.
Nous ne sommes qu’au début de cette véritable révolution où la traduction automatique, la reconnaissance vocale seront utilisées de manière complètement « transparente » dans notre quotidien.