Il n’y a pas une journée sans que nous recevions des nouvelles informations sur l’Intelligence Artificielle et sur ses différentes déclinaisons.
En plus de CHAT-GPT, de nombreuses solutions OpenSource sont maintenant disponibles qui permettent d’utiliser ce moteur d’inférence conversationnel en « local » sur votre machine.
Les projets Auto-GPT, Vicuna, Dolly, LLama, GPT4ALL ne sont que des exemples de solutions Open Source basées sur le LLM (Large Language Model) qui vous permettent d’exploiter vos modèles dans votre propre environnement et de tirer parti ainsi de vos données d’entreprise ou personnelles.
Tous ces projets nécessitent néanmoins d’avoir une machine avec suffisamment de mémoire et de disque pour pouvoir traiter des modèles à plus de 7 milliards de paramètres (pour les plus petits !). Cela limite donc encore son utilisation pour le commun des mortels.
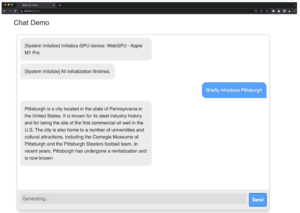
Comment utiliser votre navigateur pour accéder à votre modèle localement
Le projet WEB-LLM souhaite répondre à cette problématique en proposant d’embarquer le modèle LLM directement au sein de votre navigateur Web. Pour réaliser ce tour de force, plusieurs postulats sont requis :
Le projet ne fonctionne que sur la version expérimentale de Google Chrome avec la fonctionnalité WEBGPU (Chrome 113) dédiée à la manipulation d’images complexes et au traitement des calculs « lourds », nécessaires pour les modèles IA.
Le système utilise également le compilateur Apache TVM dédié à l’optimisation des requêtes traitées pour le Machine Learning.
Le principe simplifié du projet est le suivant : Le modèle IA initial est compilé par TVM, traité unitairement en sous fonctions python et enfin passé sous la moulinette de la « Quantization » : c’est à dire par une opération qui réduit fortement son empreinte mémoire grâce à une représentation 8 bits des entiers plutôt que dans l’utilisation d’une représentation 32 bits en virgule flottante pour stocker et traiter les informations.
Par ce biais, un modèle de 7 milliards de paramètres peut s’intégrer dans la mémoire de votre ordinateur et dans le cache de votre navigateur (avec des pertes de précision néanmoins)
Vous pouvez dès lors utiliser une variante du modèle Vicuna directement sous votre navigateur sans connexion Internet, simplement en exploitant le cache de votre navigateur et la puissance de votre CPU/GPU.
Il est alors possible d’échanger avec l’agent conversationnel comme vous le feriez avec CHAT-GPT mais au sein de votre navigateur et avec votre propre modèle !.
Le temps de chargement initial est encore un peu long car le modèle doit être importé dans l’espace disque mais les résultats sont déjà impressionnants en utilisation courante.
Ce ne sont que les prémices des futures solutions qui vont intégrer l’IA sur tout type de machines (téléviseurs, distributeurs, nano-machines etc..)
L’IA « embarqué » risque de rythmer notre quotidien proche alors êtes vous prêts à converser avec votre brosse à dents ?
Rémy Poulachon